起因
为了方便复习,想把微助教上的题目爬取出来。
为了随堂测试看题目的答案才开始折腾的
开撸
在微信中开启控制台步骤略过,用HttpCanary等抓包软件也行或直接抓openid,在浏览器中打开
https://v18.teachermate.cn/wechat-pro-ssr/?openid=自己抓&from=wzj
随便点开组卷,查看请求
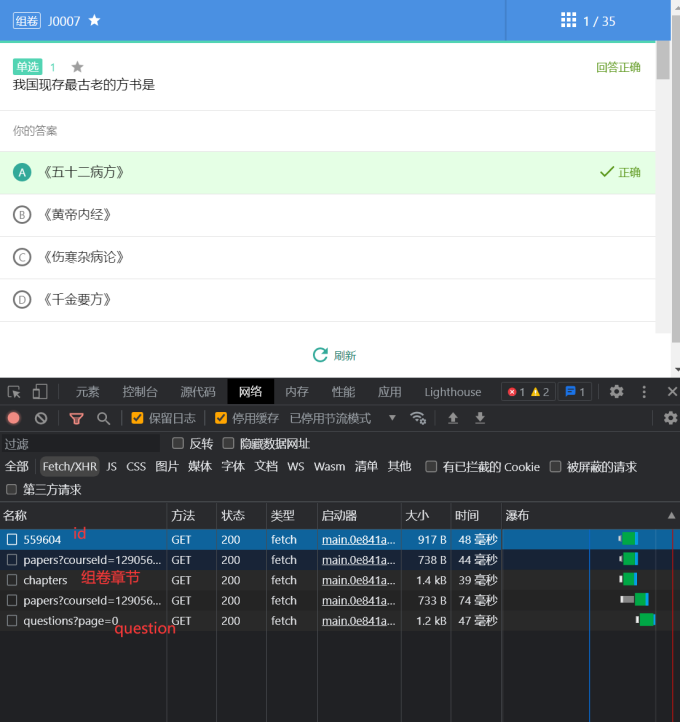
重点关注question
GET /wechat-api/v3/students/papers/559604/questions?page=0 HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cache-Control: no-cache
Connection: keep-alive
Content-Type: application/json
Cookie: session=eyJvcGVuSWQiOiI5NmY0OGJhOGQzNDVlY2VhNjRlMDg2OGFhZWFlNWMyMCJ9; session.sig=OSm07LWIepyEqLLqYjKrvGmDUWs
DNT: 1
Host: v18.teachermate.cn
Pragma: no-cache
Referer: https://v18.teachermate.cn/wechat-pro-ssr/student/answer-questions/1290563
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36
openId: 96f48ba8d345ecea64e0868aaeae5c20
sec-ch-ua: " Not A;Brand";v="99", "Chromium";v="102"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"可以看到请求的地址包含两个关键参数559604和page=0其中第一个参数就是组卷的id,而第二个则是组卷页码
查看一下响应

看到5题为一页,随便点开一题看一下
{
"id": 20644533,
"code": null,
"content": "<p>我国现存最古老的方书是</p>",
"type": 1,
"alias": null,
"difficulty": 1,
"minChosen": null,
"maxChosen": null,
"isObjective": 1,
"blankNum": null,
"isAnswered": 1,
"isCorrect": 1,
"isSet": 0,
"timingOpen": null,
"summary": "我国现存最古老的方书是",
"answerContent": [
{
"content": "<p>《五十二病方》</p>",
"rank": 0,
"answer": true
},
{
"content": "<p>《黄帝内经》</p>",
"rank": 1,
"answer": false
},
{
"content": "<p>《伤寒杂病论》</p>",
"rank": 2,
"answer": false
},
{
"content": "<p>《千金要方》</p>",
"rank": 3,
"answer": false
}
],
"review": "",
"answer": [
{
"rank": 0,
"isCorrect": 1
}
]
}可以看到题目的id、content、summary、answerContent其中id可能是题目的编号,content是页面显示的内容,因为含有p标签就使用summary的内容作为题目,answerContent则是选项。
answerContent含有三个键值对content rank answer
content选项文本
rank选项序号
answer是否为答案,true为正确答案 false则不是
(当初就是因为看到这个,才开始想能不能在还没提交的时候就看到正确答案。如果可以,随堂测试都是小意思)
2023.5.23日更新:实测不行
接下来就可以开始敲代码了,最后会写出wzj.md的markdown文件,如果组卷没有开启显示正确答案就没办法了
#安装依赖
pip install requests#爬组卷
#感谢ChatGPT的支持
#填入id和openid
import requests
import json
id =
pageNum = 0
payload = {}
headers = {
'openId': ''
}
Noforbid = True
i = 1
while Noforbid:
url = "https://v18.teachermate.cn/wechat-api/v3/students/papers/"+str(id)+"/questions?page="+str(pageNum)
response = requests.request("GET", url, headers=headers, data=payload)
#print(response.text)
pageNum = pageNum+1
jsonData = json.loads(response.text)
if jsonData == []:
Noforbid = False
for data in jsonData:
# print(data)
answer = data["answerContent"]
# mode=a 追加到文件的最后
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write("### "+str(i)+"."+data["summary"])
fb.write('\r\n')
i=i+1
for choice in answer:
if choice['answer'] == True:
correctAnswer = chr(choice['rank']+65)
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write(chr(choice['rank']+65)+"."+choice['content'])
fb.write('\r\n')
if choice['rank']==3:
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write("> "+"正确答案:"+correctAnswer)
fb.write('\r\n')
print("提取完成")同时也折腾了用于爬取单题的,因为没开启显示正确答案,所以只会爬取已选择的答案。判断题的爬取存在些许问题,影响不大。
#填入id和openid
import requests
import json
id =
pageNum = 0
payload = {}
headers = {
'openId': ''
}
Noforbid = True
questionId=[]
while Noforbid:
url = "https://v18.teachermate.cn/wechat-api/v3/students/questions?courseId="+str(id)+"&page="+str(pageNum)
response = requests.request("GET", url, headers=headers, data=payload)
pageNum = pageNum+1
jsonData = json.loads(response.text)
if jsonData['questions'] == []:
Noforbid = False
for data in jsonData['questions']:
questionId.append(data["id"])
for id in questionId:
questionUrl= 'https://v18.teachermate.cn/wechat-api/v3/students/questions/'+str(id)
response = requests.request("GET", questionUrl, headers=headers, data=payload)
question = json.loads(response.text)
code = question['code']
summary = question['summary']
try:
rank = question['answer'][0]['rank']
except :
print("未答题")
print(code + summary)
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write("### "+code+"."+summary)
fb.write('\r\n')
for answer in question['answerContent']:
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write(answer['content'])
fb.write('\r\n')
if answer['rank'] == rank:
chosenAnswer = answer['content']
with open('wzj.md', 'a', encoding='utf-8') as fb:
fb.write("> 已选:"+chosenAnswer)
fb.write('\r\n')
print("提取完成")效果展示
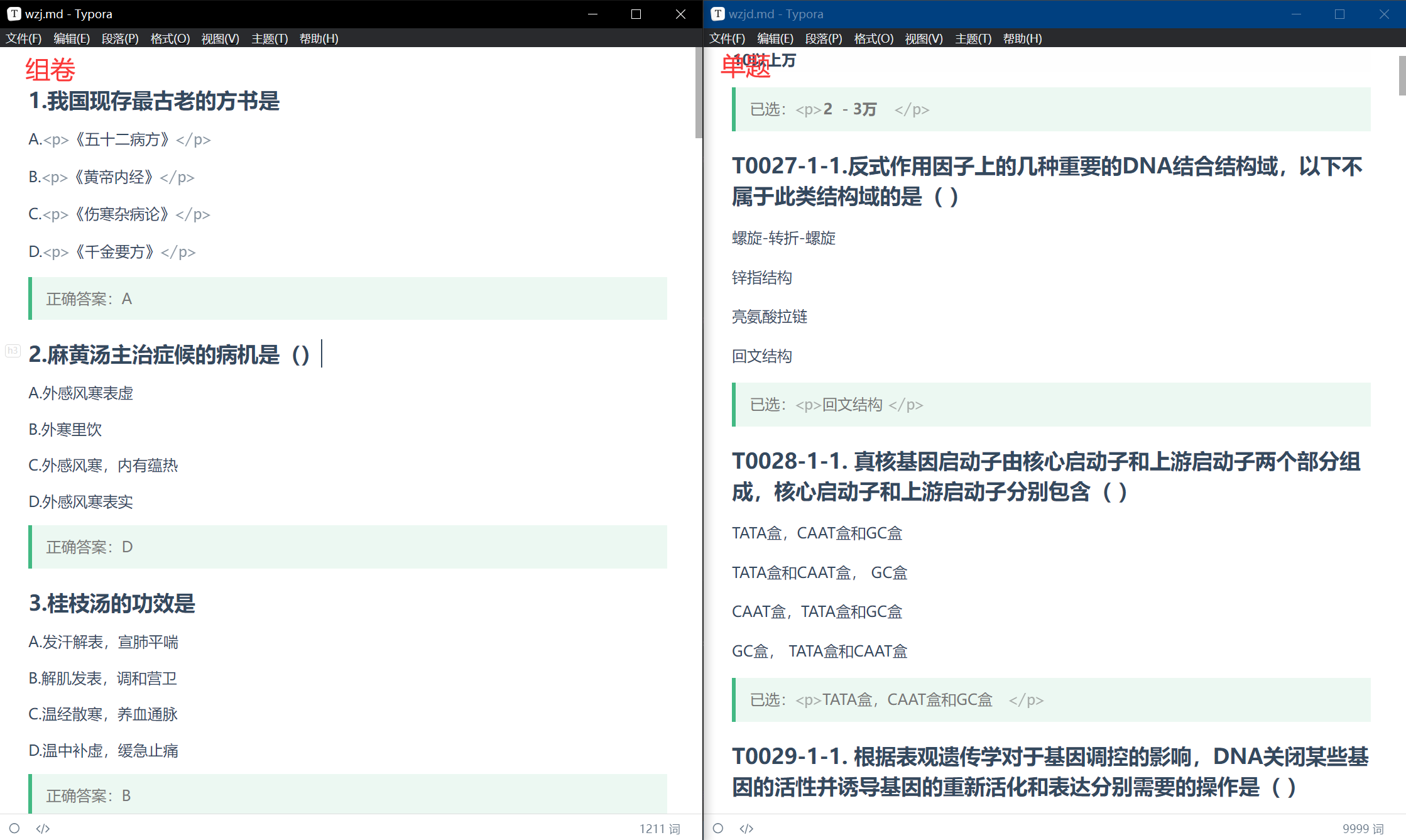
编辑器主题不同,显示效果可能有差异
